

Тексты на коммерческих сайтах часто воспринимают как техническую необходимость. Дескать, лишь бы что-то было, и желательно бесплатно. Отсюда появляются текстовые заглушки, скопированный у конкурентов контент или грубый рерайт. Развитие нейросетей только усугубило ситуацию: теперь кажется, что вопрос о создании контента можно закрыть быстрее и проще. Но проблема в том, что и поисковые системы не стоят на месте.
Алгоритмы перешли от сканирования ключей к анализу смыслов, полезности материала и поведения пользователей. А массовое появление ИИ-контента ускорило развитие поисковиков и повысило чувствительность к некачественным текстам. Именно поэтому попытки сэкономить на контенте все чаще приводят не к росту, а к потере трафика. В этой статье покажу, почему уникальность текстов до сих пор должна быть в приоритете, и разберу основные способы экономии предпринимателей на контенте.
Зачем поисковикам тексты на сайтах
Текст на странице – основной источник данных для поисковой системы. Алгоритм читает его и пытается понять сразу несколько вещей: тематику страницы, какую задачу пользователя закрывает, и релевантность конкретным поисковым запросам. Без внятного текстового сигнала поисковик не может корректно определить семантическое ядро страницы и понять, по каким запросам ее вообще имеет смысл ранжировать.
Поисковые системы анализируют не только наличие ключевых слов и их плотность, но также оценивают смысловую цель текста, его структуру, логику изложения и полноту ответа на пользовательский запрос. Дополнительно учитывают поведенческие метрики: время на странице, глубину просмотра, показатель отказов и возвраты в поиск. Если пользователь открыл страницу, прочитал пару строк и вернулся в выдачу – это негативный сигнал. Если остался, прокрутил до конца, перешел на другие разделы – позитивный.
Уникальность текста в этой логике – не процент совпадений в сервисах антиплагиата. Поисковики оценивают степень смыслового отличия страницы от других документов в выдаче. Вы можете получить 100% уникальности, но при этом создать очередной пересказ информации, которая уже есть на десятках сайтов.
Получается, важно различать техническую уникальность и смысловую оригинальность. Первая показывает отсутствие текстовых совпадений, вторая – наличие новой ценности для пользователя. Текст может быть уникальным по формулировкам, но неоригинальным по сути: те же советы, те же выводы, та же структура подачи. Поисковик это увидит через поведенческие факторы: пользователи будут уходить, потому что ничего нового не нашли.
Массовое появление ИИ-контента только усилило эту тенденцию. Для поисковых систем это новый вызов: алгоритмы стали лучше распознавать шаблонные тексты, активнее учитывать поведенческие сигналы и сильнее опираться на смысл и реальную полезность страницы. Именно здесь возникает ключевая проблема. В попытке сэкономить время и бюджет бизнес использует стандартные способы «обойти» требования поисковиков к контенту.
Основные способы «обмануть» поисковики и их последствия
Когда требования к контенту кажутся слишком сложными или трудозатратными, в ход идут разные хитрости. Они только на первый взгляд выглядят логично (с точки зрения экономии времени и бюджета), но впоследствии чаще приводят к проблемам с индексацией и ранжированием сайта.
Способ 1. Опубликовать абстрактный и водянистый текст
Существует заблуждение, что текст нужен, чтобы формально заполнить страницу. Поэтому достаточно написать несколько абзацев с общими фразами про компанию, качественные услуги и индивидуальный подход. Иногда в статьи вставляют ключевые слова из семантического ядра, иногда генерируют с нейросетью просто ради объема, без привязки к конкретному интенту.
Для поисковой системы такой контент не решает ни одной задачи. Алгоритм не может определить тематику страницы, потому что текст не фокусируется на конкретной теме – не закрывает ни информационный, ни коммерческий запрос. Семантика получается размытой, LSI-связи отсутствуют, а релевантность запросам нулевая.
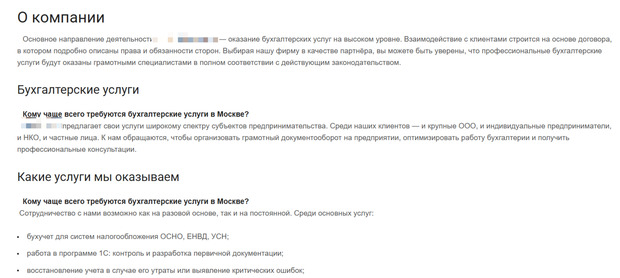
Посмотрите на пример выше. Бухгалтерские услуги – конкурентная ниша, особенно в столице, поэтому к текстам нужно относиться еще внимательнее. Фразы вроде «на высоком уровне», «грамотные специалисты» не убеждают ни людей, ни поисковые системы. В результате страница не получает показов по целевым запросам и не попадает даже в топ-50 по значимым ключам из кластера. Поисковик просто не понимает, для каких запросов ее ранжировать.
Способ 2. Разместить базовую текстовую заглушку
При запуске сайта разработчики часто используют текстовые заглушки вроде «Раздел в разработке». Это технический контент, который должен существовать только на этапе тестирования. Проблема в том, что иногда сайт запускают в продакшн, не заменив эти заглушки реальными текстами – что сигнализирует поисковику о низком качестве страницы.
Лучше временно закрыть страницу от индексации через robots.txt, пока не появится нормальный текст. В противном случае поисковой системой такая страница без ключей и LSI воспринимается как пустая. Алгоритм видит набор бессмысленных символов или служебных фраз и не может определить ни тематику, ни релевантность каким-либо запросам. Страница фактически не участвует в ранжировании.

Посмотрите на пример. Если у вас, допустим, еще не готовы статьи для блога, вместо заглушек лучше добавить несколько новостей из отрасли или короткий анонс будущих материалов – это хотя бы позволит поисковику понять тематику раздела.
Если технические заглушки остаются на сайте дольше нескольких дней после индексации, поисковик может расценить это как незавершенный или заброшенный проект. Это негативно влияет на общий уровень доверия к домену. В результате даже те страницы, где текст нормальный, могут ранжироваться хуже.
Способ 3. Взять готовые тексты у конкурентов
Логика здесь простая: если страница конкурента уже хорошо ранжируется по целевым запросам, значит, текст на ней правильный. Остается взять его целиком или с минимальными правками и разместить у себя. Иногда контент копируют дословно, иногда прогоняют через рерайт, рассчитывая, что алгоритмы не заметят разницы.
Для поисковой системы такая страница – вторичный документ. Алгоритмы достаточно точно определяют первоисточник по дате первой индексации. Дополнительно учитывают возраст домена, уровень доверия, ссылочный профиль и историю сайта. Даже если скопированный текст сам по себе качественный и релевантный запросам, при прочих равных приоритет в ранжировании остается у оригинального источника с более высоким авторитетом.
В результате в топ-10 выдачи продолжает находиться конкурент. Скопированная страница либо вообще не попадает в индекс, либо занимает нестабильные позиции за пределами первых страниц выдачи. При этом бизнес получает дополнительные риски: от репутационных до юридических, связанных с нарушением авторских прав. К слову, за копирование текстов без согласия авторов с вас могут взыскать компенсацию, а при коммерческом использовании и административный штраф. Ну и блокировка самой страницы тоже может быть.
Сама логика анализа конкурентов правильная. Действительно, нужно смотреть на сайты из топ-10. Только не для того, чтобы копировать их целиком, а чтобы понять акценты. Например, все ваши конкуренты-автодилеры из выдачи рассказывают на главной про условия кредитования или trade-in в блоке с преимуществами. Значит, это важно для пользователей и вам тоже стоит раскрыть эти вопросы, но своими словами и со своими условиями. Анализ конкурентов помогает понять структуру контента и ожидания аудитории, но не заменяет создание уникального текста.
Способ 4. Написать хороший текст и продублировать его везде
На первый взгляд эта хитрость выглядит более осмысленной. Проблема в том, что для поисковой системы такие страницы становятся смысловыми дублями. Алгоритм видит несколько URL с идентичным или почти идентичным содержанием и не понимает, какую страницу считать основной для ранжирования. Каждая из них претендует на одни и те же запросы из семантического ядра, не усиливая, а ослабляя друг друга.
В результате возникает каннибализация. Страницы начинают конкурировать между собой в выдаче за одни и те же позиции. Их релевантность размывается, ссылочный вес распределяется между несколькими URL, и ни один из них не получает возможности стабильно закрепиться в топ-10. Иногда позиции «прыгают» от одной страницы к другой, иногда органический трафик просто не растет без очевидной причины.
Даже качественный SEO-текст перестает работать, если не привязан к конкретной странице и конкретному интенту пользователя. Для поисковика важно не абстрактное «качество контента», а четкое соответствие между URL, кластером запросов и типом интента: информационным, навигационным или коммерческим.
Способ 5. Сделать минимальный рерайт источника
Берем хороший текст, заменяем слова на синонимы – готово! Формально текст становится другим и проходит проверку на уникальность, но для поисковой системы такие изменения почти ничего не значат. Ведь алгоритмы анализируют не набор слов, а смысл. Если логика изложения, аргументы и структура остаются прежними, поисковик определяет это как смысловую копию.
Синонимайзинг сильно ломает читаемость и почти всегда приводит к канцеляриту:
- «Организовать бизнес-встречу» превращается в «инициировать мероприятие коммуникационного характера».
- «Быстро решить задачу» становится «оперативно реализовать поставленную цель».
Текст перестает звучать естественно, его сложно читать и понимать. При этом хороший рерайт с сохранением инфостиля займет столько же времени, сколько написание текста с нуля.
Когда контент не предлагает оптимального качества и уникальности, аудитория не находит его достойным для чтения, растет показатель отказов. Человек открывает страницу, видит перегруженные конструкции, не находит прямого ответа на запрос и уходит. Поисковик отмечает это как негативный поведенческий сигнал и понижает страницу в ранжировании. В итоге текст не усиливает видимость сайта в органической выдаче и не дает прироста по целевым запросам. Поисковики давно научились отличать переработку смысла от механической замены слов и не считают такой контент полноценным для высоких позиций.
Способ 6. Заимствовать контент у правообладателей
Ситуация похожа на «работу» с текстами конкурентов, но речь не про чистый плагиат, а про копирование с разрешением. Такое бывает, когда есть проверенный источник данных. Например, онлайн-магазины часто размещают в товарных карточках официальные материалы от производителей или поставщиков и даже открыто ссылаются на них. Информация в таком случае и точная, и проверенная: продукт описан со всеми техническими характеристиками.

Это описание шин на сайте производителя.
А здесь уже онлайн-магазин.
И еще один.
Проблема в том, что таким описанием, скорее всего, пользуются десятки, а иногда и сотни других компаний. Поэтому и результат будет как при копировании текстов конкурента. Приоритет в ранжировании получает источник с максимальным авторитетом – обычно это сам производитель, крупный агрегатор или маркетплейс с развитым ссылочным профилем. Если вы продаете тот же товар, что и другие, единственный способ выделиться в органической выдаче – рассказать о нем по-своему:
- Добавить детали использования.
- Показать реальные кейсы применения, конкретные цифры из практики.
- Рассказать о личном опыте работы с продуктом.
- Объяснить, для какой целевой аудитории этот продукт подходит лучше всего.
- Создать сравнительные таблицы или авторскую экспертную позицию по теме.
Именно эти элементы делают текст не просто оригинальным, а ценным для ранжирования.
Выводы
Напомню SEO-истину: поисковикам всегда нужны понятные сигналы о том, что это за страница, какую задачу она решает и чем отличается от десятков похожих в выдаче. Именно эту роль и выполняет уникальный контент.
Источники изображений: данные поисковой выдачи и отдельных сайтов из открытого доступа.
Также читайте:






































1. Пишите сами!
2. Обеспечьте практическую пользу для читателя
И тогда поисковики вас хорошо проранжируют и читатели будут благодарны )))
Хорошо работает схема:
1. Вычисляем реальных спецов в компании
2. Просим их поделиться практическими советами в любой форме - хоть наговор на диктофон
3. Литературно обрабатываем, превращая тексты "как можно легко прикрутить эту хреновину к той..." в нечто, проходящее цензуру
4. Размещаем на сайте )))
Как показывает опыт, "пишите сами" часто заканчивается на первом тексте из-за нехватки сил и времени. Сомневаюсь, что кто-то плагиатит тексты прям из лучших побуждений, а не потому, что он в цейтноте или в растерянности. Тем не менее, негативные последствия таких действий осознаются не всегда, отсюда и статья.
Что касается предложенной вами схемы, то она отличная, но работает, в основном, с информационными статьями. С продуктовыми карточками будет сложнее, а с коммерческими продающими текстами она вообще невозможна, потому что единственный эксперт, который может рассказать про ваш бизнес, - это и есть вы сами, как правило.